
In the ever-evolving landscape of big data, efficient processing is crucial for organizations to derive meaningful insights from massive datasets. Apache Spark has emerged as a powerful open-source, distributed computing system designed to address the challenges of big data processing. PySpark, the Python API for Spark, has gained immense popularity for its ease of use and seamless integration with the Python programming language. In this blog, we will delve into the world of Spark and PySpark, exploring their features, advantages, and how they contribute to revolutionizing big data analytics.
What is Apache Spark?
Apache Spark is a fast and general-purpose distributed computing system that provides an in-memory data processing engine for big data. Originally developed at the University of California, Berkeley's AMPLab, Spark has quickly become the go-to framework for data processing due to its speed, ease of use, and versatility. It supports various programming languages, including Scala, Java, and Python, making it accessible to a wide range of developers.

What are the different ways to work with Spark ?
- 1. Spark Shell: Spark provides interactive shells for Scala (spark-shell), Python (pyspark), and R (sparkR). These shells allow you to interact with Spark using a command-line interface, execute Spark commands, run queries, and perform data manipulations interactively. You can use the Spark shell for experimentation, data exploration, and quick prototyping.
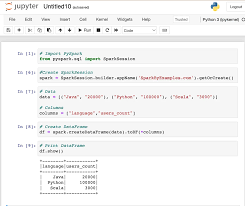
- 2. Notebooks: Jupyter Notebook and Apache Zeppelin are popular notebook environments that support Spark integration. Notebooks allow you to create and share documents containing code, visualizations, and narrative text. You can write Spark code in notebook cells, execute them interactively, and visualize the results in real-time.
- 3. Elastic MapReduce: EMR (Elastic MapReduce) refers to the managed Spark service provided by Amazon Web Services (AWS). EMR allows you to run Apache Spark on a fully managed cluster, taking advantage of AWS infrastructure and services.
- 4. DataBricks: Databricks is a unified analytics platform that provides a collaborative and cloud-based environment for processing and analyzing big data, including Apache Spark workloads. Databricks simplifies the deployment, management, and scaling of Spark clusters, enabling users to focus on data analysis and insights
Key Features of Apache Spark:
- Speed: Spark's in-memory processing enables significantly faster data processing compared to traditional disk-based systems. This is achieved through the resilient distributed datasets (RDDs) and Spark's DAG (Directed Acyclic Graph) execution engine.
- Ease of Use: Spark provides high-level APIs in multiple languages, making it accessible to developers with different skill sets. Its user-friendly APIs simplify complex data processing tasks, reducing the learning curve for new users.
- Versatility: Spark supports various workloads, including batch processing, interactive queries, streaming analytics, and machine learning. This versatility makes it suitable for a wide range of applications, from data warehousing to advanced analytics.
Introduction to PySpark:
PySpark is the Python API for Apache Spark, allowing developers to harness the power of Spark using the Python programming language. PySpark exposes the Spark programming model to Python, enabling seamless integration with popular Python libraries and frameworks. This is particularly advantageous for data scientists and engineers who are already familiar with Python and its extensive ecosystem.

Advantages of PySpark:
- Pythonic Syntax: PySpark allows developers to leverage Python's concise and expressive syntax, making code more readable and maintainable. This is especially beneficial for data scientists and analysts who may not have a strong background in Scala or Java.
- Integration with Python Ecosystem: PySpark seamlessly integrates with popular Python libraries such as NumPy, pandas, and scikit-learn. This enables data scientists to leverage their existing Python code and take advantage of the rich ecosystem of Python tools for data analysis and machine learning.
- Interactive Data Exploration: PySpark is well-suited for interactive data exploration and analysis. The interactive Python shell (PySpark Shell) facilitates quick prototyping and experimentation, allowing users to interact with large datasets in real-time.
How to create Spark Session and what is different between spark context and spark session?
Prerequisites: Before you start creating RDDs, make sure you have basic knowledge of PySpark and Apache Spark. You should also have a JDK installed on your machine.
In Apache Spark, a SparkSession is the entry point for interacting with structured data (e.g., DataFrames) and performing operations on them. It is available since Spark 2.0 and combines functionality previously provided by SQLContext and HiveContext
Create a SparkSession
- from pyspark.sql import SparkSession
- # Create a SparkSession
- spark = SparkSession.builder.appName("example").getOrCreate()
Let's understand the difference between SparkContext and SparkSession
SparkContext:
- In earlier versions of Spark (prior to 2.0), SparkContext was the entry point to any Spark functionality. It represented the connection to a Spark cluster and was used to create RDDs (Resilient Distributed Datasets) and perform low-level operations.
- It was used for operations that didn't require a structured API (like DataFrames) but instead worked with RDDs, which are more low-level distributed collections of objects.
- It was typically available as sc when you started a PySpark shell.
SparkSession:
- SparkSession is a higher-level API that provides a unified entry point for reading data, performing operations, and writing results. It includes the functionality of SQLContext and HiveContext and provides a more user-friendly interface for working with structured data.
- It can work with DataFrames, which are distributed collections of data organized into columns.
- SparkSession is used for working with structured APIs like DataFrames and Datasets.
Example of creating a SparkContext
- from pyspark import SparkContext
- sc = SparkContext(appName="example")