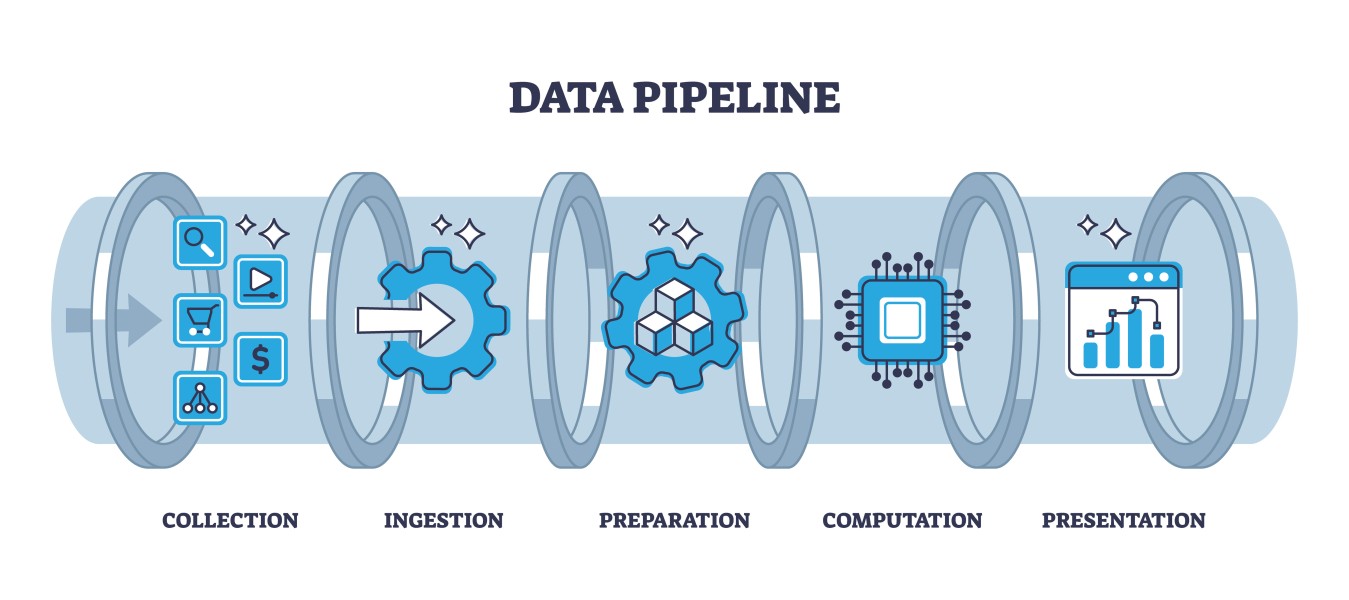
ETL Data Pipeline: Unraveling the Core of Data Integration
ETL, which stands for Extract, Transform, Load, is a fundamental process in the world of data management and analytics. An ETL data pipeline is a systematic and automated approach to collecting, processing, and loading data from diverse sources into a destination where it can be analyzed, visualized, or used for decision-making. Let's break down the components of an ETL data pipeline:
Extract:
- Source Systems: The process begins by extracting data from various source systems, which could include databases, applications, flat files, APIs, or external data feeds. These sources may contain raw, unstructured, or semi-structured data.
- Connectivity: ETL tools establish connections to source systems, pulling data in a structured format for further processing. This phase involves understanding the source data structure, schema, and ensuring compatibility.
Transform:
- Data Cleaning and Validation: Raw data is often messy and may contain errors. The transformation phase involves cleaning and validating the data to ensure accuracy and consistency. This includes handling missing values, correcting errors, and standardizing formats.
- Structural Changes: Data may undergo structural changes to meet the requirements of the destination system. This could involve aggregating data, splitting or merging columns, and converting data types.
- Enrichment: Additional data from external sources might be integrated to enrich the existing dataset, providing more context and depth for analysis.
Load:
- Destination Systems: The transformed data is loaded into a destination system, which could be a data warehouse, database, or data lake. The destination system is optimized for analytics and reporting.
- Indexes and Relationships: Indexing and establishing relationships within the destination system optimize query performance and facilitate efficient data retrieval.
- Historical Data: In some cases, historical data is maintained, allowing for time-based analysis and tracking of changes over different periods.
In the ever-expanding landscape of big data, data engineers play a pivotal role in designing and implementing robust data infrastructure. Leveraging a stack of powerful tools such as AWS EMR, PySpark, DynamoDB, S3, Athena, Glue, CodeCommit, CodePipeline, and Airflow, these professionals orchestrate complex data pipelines that transform raw data into valuable insights. Let's delve into the key components and the role of a data engineer in this ecosystem.

Apache Spark:
Apache Spark is a powerful open-source distributed computing framework designed for speed and ease of use in processing large-scale data. Its in-memory processing capabilities significantly accelerate data analytics, enabling the seamless handling of vast datasets across distributed clusters. Spark's resilient distributed datasets (RDDs) provide fault-tolerant, parallelized data processing, ensuring robustness in the face of node failures. With a unified platform supporting batch processing, interactive queries, real-time analytics, and machine learning, Spark eliminates the need for disparate tools, simplifying the development and management of big data applications. Spark's ecosystem, including Spark SQL, MLlib for machine learning, and GraphX for graph processing, amplifies its versatility, making it a go-to solution for organizations seeking scalable and efficient solutions for diverse data processing tasks.
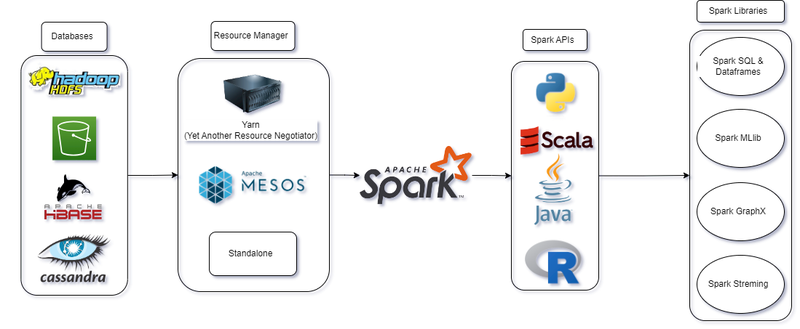
AWS Data Engineering Ecosystem:
Amazon Web Services (AWS) provides a robust suite of services tailored for data engineers, enabling the creation of scalable and efficient data solutions. Amazon S3 acts as a secure and scalable object storage service, while Amazon EMR simplifies the deployment of distributed data processing frameworks. AWS Glue automates ETL processes, supporting languages like Python and Scala, and DynamoDB serves as a fully managed NoSQL database for flexible data storage. Redshift offers high-performance data warehousing, Lambda enables serverless computing, and Kinesis facilitates real-time streaming data processing. AWS Step Functions orchestrate workflows seamlessly, and Aurora provides a managed relational database solution. With services like Data Pipeline and a myriad of additional tools, AWS empowers data engineers to design end-to-end data pipelines, from ingestion to analytics, within a comprehensive and integrated ecosystem.

Apache Airflow in Data Engineering:
Apache Airflow plays a pivotal role in data engineering by providing a flexible and extensible platform for orchestrating complex data workflows. Its importance lies in its ability to automate, schedule, and monitor the execution of diverse tasks within data pipelines. Airflow enhances workflow visibility, allowing data engineers to design, manage, and visualize the end-to-end data processes efficiently. With a rich set of pre-built connectors and the ability to integrate with various data storage and processing systems, Airflow facilitates seamless coordination and execution of tasks, ensuring reliability and repeatability in data workflows. Its open-source nature and active community contribute to its adaptability, making it an indispensable tool for data engineers seeking to streamline and optimize data processing operations. Working with Airflow involves defining workflows as directed acyclic graphs (DAGs), configuring tasks, setting dependencies, and leveraging the scheduler to automate the execution of tasks based on specified conditions or schedules. This enables data engineers to focus on designing robust data pipelines while Airflow handles the orchestration and monitoring aspects, ultimately contributing to the efficiency and reliability of data engineering processes.
Data Engineering Workflow:
The typical data engineering workflow involves ingesting raw data from diverse sources into the pipeline, transforming and cleaning the data using PySpark on AWS EMR clusters, and storing the processed data in DynamoDB or S3. Airflow schedules and monitors these tasks, ensuring the reliability and repeatability of the entire process.