
AWS Glue, an integral service within the Amazon Web Services (AWS) ecosystem that revolutionizes the way we handle data integration, ETL (Extract, Transform, Load) processes, and data preparation.

Glue Crawlers
The CRAWLER creates the metadata that allows GLUE and services such as ATHENA to view the S3 information as a database with tables. That is, it allows you to create the Glue Catalog.
Glue Job
An AWS Glue job encapsulates a script that connects to your source data, processes it, and then writes it out to your data target. Typically, a job runs extract, transform, and load (ETL) scripts. Jobs can also run general-purpose Python scripts.
Glue Data Catalog
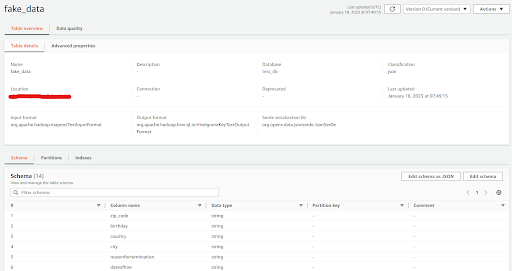
AWS Glue Data Catalog tracks runtime metrics, and stores the indexes, locations of data, schemas, etc. It basically keeps track of all the ETL jobs being performed on AWS Glue. All this metadata is stored in the form of tables where each table represents a different data store.
Architecture for sample project to show the AWS Glue crawlers and Glue data catalog
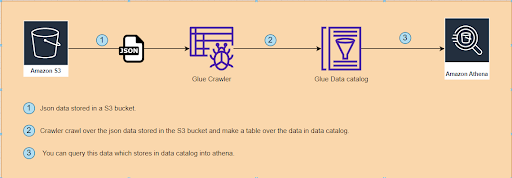
AWS Glue crawlers deployment through serverless framework
We used serverless framework to deploy the AWS Glue crawlers in which what we have done is we created a YAML configuration file, in this configuration includes the definition of an AWS Glue Crawler resource named "TableGlueCrawlerPractice." This crawler is set up to crawl a specified S3 path and update a Glue database using environment variables. Additionally, it specifies a role with necessary permissions for the Glue Crawler's execution. The RecrawlPolicy is configured for a CRAWL_EVERYTHING behavior, and the SchemaChangePolicy is set to "LOG" updates and "DEPRECATE_IN_DATABASE" deletions. Lastly, it includes a JSON-formatted Configuration defining behavior for handling table changes during crawling operations.
It will make a crawler on AWS Glue in which it will create a database and I put the s3 path of the folder where my files are stored in the S3. In those json files there are some records stored.
Result
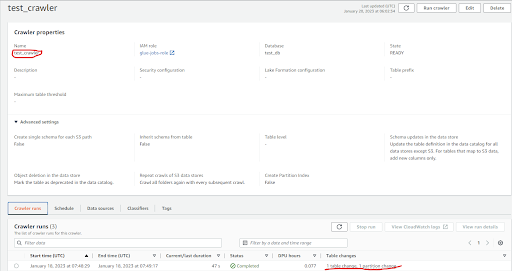
After the crawler runs successfully for the source s3 path where our json files are stored, it will create a table in our glue data catalog.
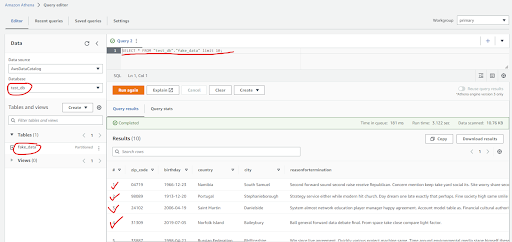
You can query this table data by using Athena.
Architecture for sample project to show the AWS Glue job

AWS Glue Job deployment through serverless framework
The resource defined is an AWS Glue Job named "test_glue_job," configured with properties such as the designated role, Glue version ('3.0'), maximum retries, number of workers, worker type ('G.1X'), timeout, and maximum concurrent runs. The job utilizes a specified script location for execution, passing various arguments like source and target paths, temporary directory, enabling Glue data catalog, metrics, continuous CloudWatch logging, Spark UI, Spark event logs path, job insights, and job bookmark options. This configuration outlines the essential parameters and environmental setups necessary for the execution and management of the AWS Glue Job within the specified AWS region.
It will create a glue job in the AWS account.
Result
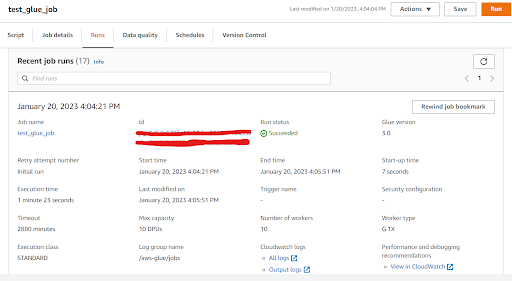
It will show the run status like this if it succeeded, failed or was in a running state.You also see the logs of the job in the cloud watch logs.
What the Glue job does?
The provided AWS Glue job script performs several data transformations and writes the processed data to an Amazon S3 bucket. It starts by reading JSON files from a specified S3 source path, removing any duplicate records found within these files. Then, it applies a schema mapping to define the structure of the data, specifying how different fields like zip code, birthday, country, and others are interpreted. Finally, the processed data is written back to another S3 location in the form of Glue Parquet files, utilizing the Snappy compression format. In essence, this script cleanses the data, organizes it according to a defined schema, and stores the transformed data back into an S3 bucket for further analysis or usage.
You should click on the Run button on the upper right corner then it will start this job.
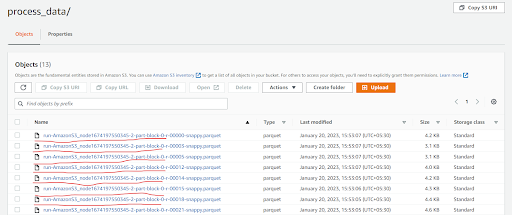
After successfully running the Glue job you can check in the S3 target path that it will create the cleaned records file in a parquet format with snappy compression.
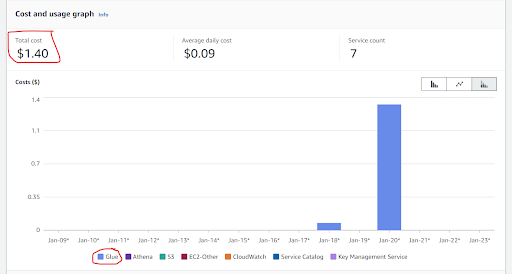
AWS Pricing for Glue Services we used for this blog
We spent around $1.40 on Glue crawlers and Glue job in which we spent $0.08 on glue crawlers and $1.33 on Glue Job as Glue job works on spark so it will use the clusters and their workers to operate that’s why Glue Job is more expensive than Glue crawlers.
AWS Glue crawlers pricing depends on the number of crawlers and the duration of crawlers run. Suppose you have only one crawler and it will run for 10 minutes to crawl over the data then it will give you a $0.07 bill.
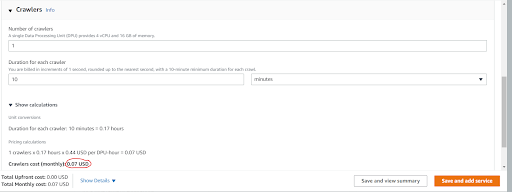
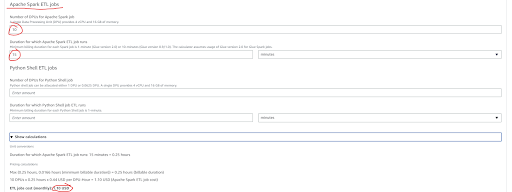
AWS Glue Job pricing depends on the number of DPUs(Data Processing Unit) and a single DPU provides 4 vCPU and 16 GB of memory. It also depends on the duration of the Glue spark job runs.
Suppose you have 1 spark job and it uses 10 DPUs and it runs for 15 mins to complete the ETL process then it will give you a $1.10 bill.
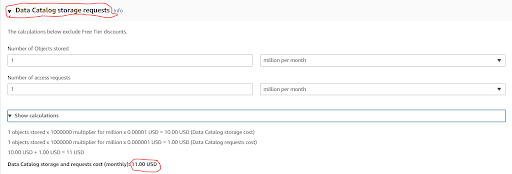
AWS data catalog pricing depends on the objects stored in the data catalog and number of access requests.
Suppose you want to store 1 million records in the data catalog and you want 1 million access requests then it will give you a $11 bill.
AWS Glue not only enhances data reliability and quality but also accelerates the journey towards data-driven decision-making. As organizations navigate the landscape of big data, AWS Glue emerges as a fundamental solution for enabling seamless and efficient data workflows within the AWS environment.